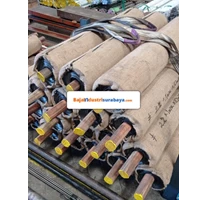
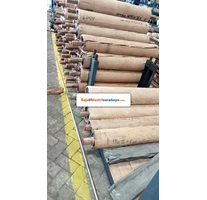
cv AIS Jual PLAT TIMAH HITAM, LEAD SHEET atau Plat Timah Hitam ini terbuat dari timah hitam dengan kadar yang sangat tinggi sehingga memiliki perlindungan yang sangat tinggi terhadap radiasi dan daya kedap suara yang sangat baik.
Dimensi Plat Timah Hitam Surabaya ini adalah
UKURAN LEBAR 1 METER TEBAL x PANJANG:
- 0.8mm X 15 meter
- 1mm x 10 meter
- 1.5mm x 7 meter
- 2mm x 10 meter
- 3mm x 7 meter
APLIKASI PLAT TIMAH HITAM adalah
Sebagai Lapisam Dinding anti radiasi X-ray ( Ruang CT Scan Dll ) di rumah sakit, perlindungan dari radiasi nuklir, dan juga sebagai bahan untuk pemberat pancing.
Pembelian Plat Timah Hitam bisa langsung menghubungi kami via WA, Email atau pun Telpon secara langsung. Kami Melayani Order secara online dengan Pengiriman yang sesuai kebutuhannya.
SALAM KENAL,
Rahmat Hidayat PHONE. 031 3989496, 082129847777, 082129846666 FAX. 031 3980197, EMAIL: INDUSTRI2034@ GMAIL.COM
#Plattimah, #JualPlatTimah, #Jualplattimahhitam, #Jualplattimahsurabaya, #Jualplatpbantiradiasi, #Jualkacapb, #Jualkacapbsurabaya, #JualplattimahmurahSurabaya, #JualPlatTimbal, #JualPlatPB
#agroindustrisurabaya #indobajasurabaya #jualtimbalsurabaya #jualtimahsurabaya #jualplatpbsurabaya